前言
昨天提到大數據的計算模式大致上可以分為批處理與流處理,還沒看過的可以先看這篇:Day03 - 大數據計算:批處理與流處理
批處理用於批次處理大量數據,流處理則通常用於處理實時數據。當企業在建立自身的大數據系統時,如伺服器日誌的監控系統,除了即時日誌分析外,往往也需要針對歷史日誌進行大規模離線分析,因此在系統架構設計上,我們需要考慮如何兼容兩種處理流程。
Lambda 架構是最經典的大數據架構,想法很直接,就是同時維護兩條流程,一條批負責批處理,另一條則負責流處理,其主要由三個層次組成:批次層、速度層 和 服務層。
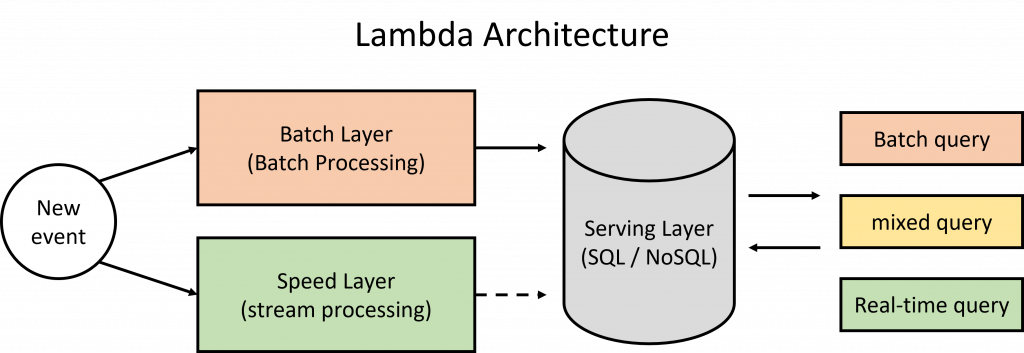
批次層 Batch Layer
速度層 Speed Layer
再次強調,Spark Streaming事實上是微批處理,不過也可以拿來處理即時數據流。
服務層 Serving Layer
速度層之產出可以直接被查詢,不一定要透過服務層,然而當查詢內容同時涉及批處理層與速度層時,服務層會使用速度層之產出。
Lambda 架構雖能同時進行批處理與流處理,然兩者間存在計算不同源以及存儲不同源的問題:
Kappa 架構是流批一體的架構,捨棄 Lambda 架構中的批處理層,僅保留速度層與服務層,其數據會被鏡像存儲到長期存儲中的 master data,用於執行批處理,其性質與在批次層內相同。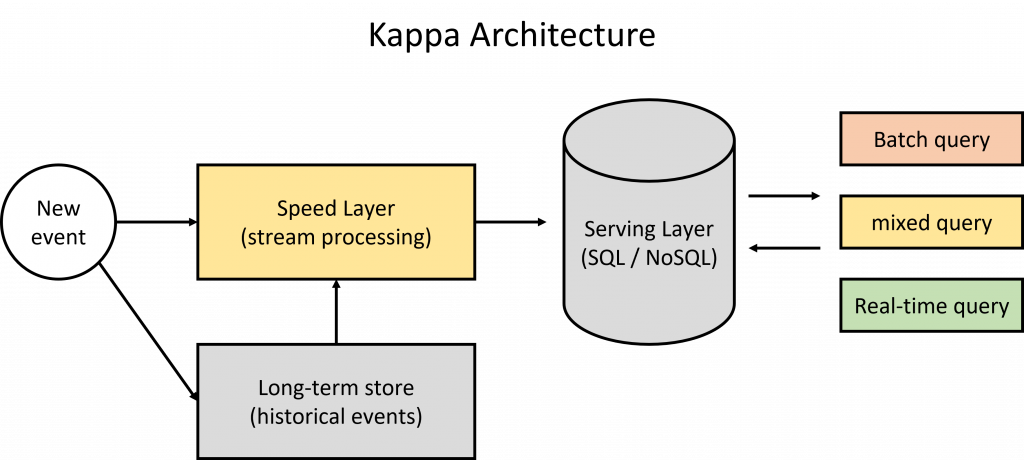
計算同源
批處理與流處理共用同一套計算引擎、代碼,開發與維護成本較低,其根本是流處理,透過重新處理事件的方式來進行批處理,通常會要求計算引擎具備 Exactly-once 的特性,以保證資料的完整性。Flink 就是支援流批一體的計算引擎。
在流處理中,一個事件的處理可能會經過多個運算子,Exactly-once 指即使在故障情況下,每個運算子都只會對事件做精確一次運算,更多細節可以參考:谈谈流计算中的『Exactly Once』特性
存儲同源
存儲系統同時滿足批數據與流數據的存儲,且能對數據進行高效的查詢與更新,解決數據不一致的問題,維護成本較低。
雖說 Kappa 架構是 Lambda 架構的改良版,但 Kappa 架構並不能完全取代 Lambda 架構,兩個架構的使用情境不完全相同,Kappa 架構本質上以流處理為主軸,適合數據持續寫入、有時間窗口的任務,反之 Lambda 有完整的批處理流程,因此適合需要對歷史數據做大量操作的任務。
明天開始將正式進入我們的第一個大數據框架: Hadoop。
巨量資料架構
大数据架构如何做到流批一体?
Flink 流批一体在字节跳动的探索与实践


 iThome鐵人賽
iThome鐵人賽